
Editor’s note: This is a guest post submitted by Mahendra Palsule, who has worked as an Editor at Techmeme since 2009. Apart from curating tech news, he likes analyzing trends in startups and the social web. He is based in Pune, India, and you can follow him on Twitter.
What’s the Next Big Thing after social networking?
This has been a favorite topic of much speculation among tech enthusiasts for many years. I think we are already witnessing a paradigm shift – a move away from simple social sharing towards personalized, relevant content.
The key element of the next big thing is the increasing significance of the Interest Graph to complement the Social Graph. While Facebook, Twitter, and Google are already working on delivering relevant content, a slew of startups are focusing exclusively on it.
Relevance is the only solution to the problem of information overload.
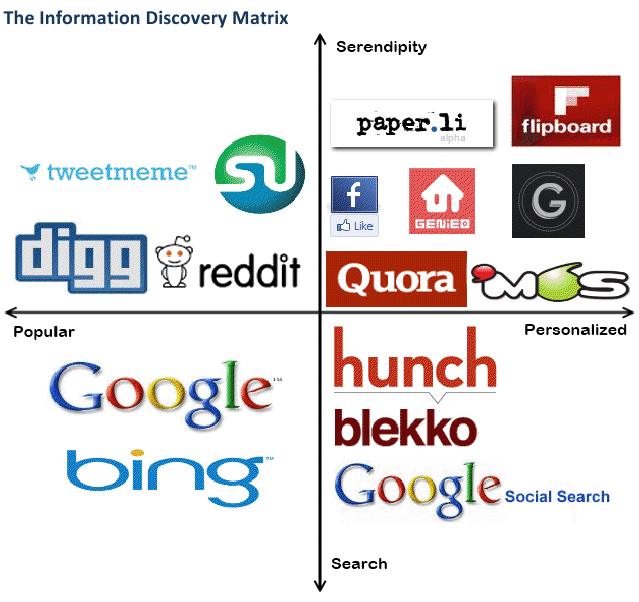
The above matrix is a representation of how the process of online information discovery has evolved over time.
Phase I: The Search Dominated Web
This is how Google began its dominance over the web two decades ago, using PageRank to surface the most popular web pages as identified by other web pages that linked to them.
Phase II: Web 2.0 With Social Bookmarking
In the Web 2.0 era, social bookmarking services gained significant traction, surfacing popular content. Sites like Reddit and StumbleUpon are hugely popular even today, driving millions of page views.
Phase III: Personalized Recommendations
Services like Hunch, GetGlue, etc. have focused on building an Interest Graph for users, to deliver personalized recommendations using a ‘taste engine’.
Phase IV: Personalized Serendipity
The latest crop of startups is focusing on personalization using a combination of Interest and Social Graphs. Personalized Serendipity is what Jeff Jarvis calls ‘Unexpected Relevance’. Examples include Gravity, my6sense, Genieo, and TrapIt.
What Exactly Is Relevance?
The battle against information overload is sometimes presented as a choice between Relevance and Popularity, where ‘relevant’ is equated to ‘personalized’ as against popular.
However, Relevance does not always mean Personalized. Relevance is very dynamic – it depends on the needs of a person at a specific point in time. There are times when users want to know about the most popular stories, and other times when they seek personalized content.
There are multiple approaches to filtering information for Relevant Content. Google, Paper.li, and PostRank are examples of algorithmic filtering, while Reddit, Hacker News use a crowdsourcing approach. Klout can be used to filter Twitter streams by influence, while Facebook uses social affinity as a filter for its newsfeed and social signals for its new Comments Plugin. Location is another high-impact signal for delivering relevant content, gaining importance in a mobile world.
In other words, Relevance spans across all the quadrants of the Discovery Matrix above, and none of the above approaches to filtering for relevance is the ‘best approach’. There is no killer approach to Relevance. Henry Nothhaft, Jr., CMO of TrapIt, described it as “the myth of the sweet spot”. The competitive edge will be with services that support multiple discovery methods, multiple filtering approaches, have flexibility, and support multiple mobile platforms.
Quora: A Showcase Of The Interest Graph
Quora has pioneered the use of the Interest Graph as a dominant signal for its newsfeed. Quora asks new users to select Topics to follow, as part of its onboarding process, which is the first revelation that Topics are as important as Users to follow.
Quora’s newsfeed is an interesting showcase of what happens when you mix an Interest Graph with a Social Graph – and the result is the mysterious addictiveness so many have experienced, but found difficult to explain. An item pops up in your newsfeed not because you were following a user, but because you were following a related topic.
This often leads to Personalized Serendipity – or Unexpected Relevance – which is why Quora gets many people hooked.
The war over the Interest Graph began between Twitter and Facebook last year, as Erick described so eloquently. So how did Quora beat them to this game?
For starters, Quora is built from the ground-up with the Interest Graph being a backbone of the framework. Twitter’s ‘Browse Interests’ is too broad and primitive to be of use, even at present. And while Facebook has a mechanism for allowing publishers to push new items to your feed, most publishers have been unaware of this functionality.
This is also the reason why Facebook’s Like Button now publishes a full news feed story. The future clearly belongs to who best captures the Interest Graph as Max Levchin and Bill Gurley put it.
The implications of a Relevance-driven web are wide-ranging and broad in scope. Better utilization of the Interest Graph by services will lead to better ad targeting, and a potential decrease in reliance on CPM/CPC-based advertising. Monetization focus will be on higher yields through transactions and subscriptions as Dave McClure once described. Online media publishers will focus on Relevance Metrics revealing engagement and time-spent on site, than primitive metrics like page views and traffic.
Social media may lose its obsession with follower numbers and traffic, evolving to context-driven reputation systems and algorithms.
Interest Graphs will be used to build Better Social Graphs. Today’s monolithic Interest Graph will get further specialized into Taste Graphs, Financial Graphs, Local Network Graphs, etc., yielding higher relevance for different needs.
The Age of Relevance beckons!